
Context
Som Connexió (https://somconnexio.coop/ ) és una cooperativa de telefonia i internet sense afany de lucre.

Des de Som Connexió es necessiten analitzar les dades de les sòcies, contractes, consums, poder fer pressupostos i previsions de futur de forma fàcil i visual.
Estat inicial
A Som Connexió ja havien començat a treballar en diversos dashboards a través de Metabase que analitzaven altes i baixes de sòcies i contractes, tant de banda ampla com de mòbil.
Un dels problemes que tenien era que no podien creuar dades de diferents orígens de dades (ERP, sistema de facturació, sistema de tiquets). També trobaven que la potència de Metabase els havia quedat justeta.
Des de Som Connexió tenien una llista de requeriments ja definits d’on volien anar avançant.
Execució del projecte
FASE I: Definició de l’arquitectura
El projecte de Som Connexió tenia certa complexitat per que calia unir diversos orígens de dades i, en alguns casos, el volum de dades no era petit (alguns milions de files per taula). Primer calia definir una arquitectura que pogués respondre a aquestes 2 necessitats.
L’arquitectura que es va fer servir és la definida al post: https://coopdevs.org/business-intelligence-per-a-leconomia-social-i-solidaria/
PostgresSQL és el nostre repositori final de dades, on es es té un esquema amb les dades directes de l’origen de dades i una altre esquema amb dades calculades.
El component FDW de postgres ens permet poder unir en una sola consulta diversos orígens de dades.
DBT ens permet persistir les dades en el que el rendiment de les consultes fetes directament amb el FDW no fos òptim.
Els DBT s’executen cada dia mitjançant un DAG d’Airflow.
Per a la capa de visualització es va triar Superset. Superset permet fer consultes a la BBDD Postgres on es té accés a tots els orígens de dades, ofereix diverses formes de visualització de les dades i permet inserir codi jinja a la consulta oferint una potència de flexibilitat més alta que altres eines.
Per tal de facilitar el desplegament i permetre la reutilització de l’arquitectura es va fer servir Ansible: https://git.coopdevs.org/coopdevs/bi/bi-provisioning
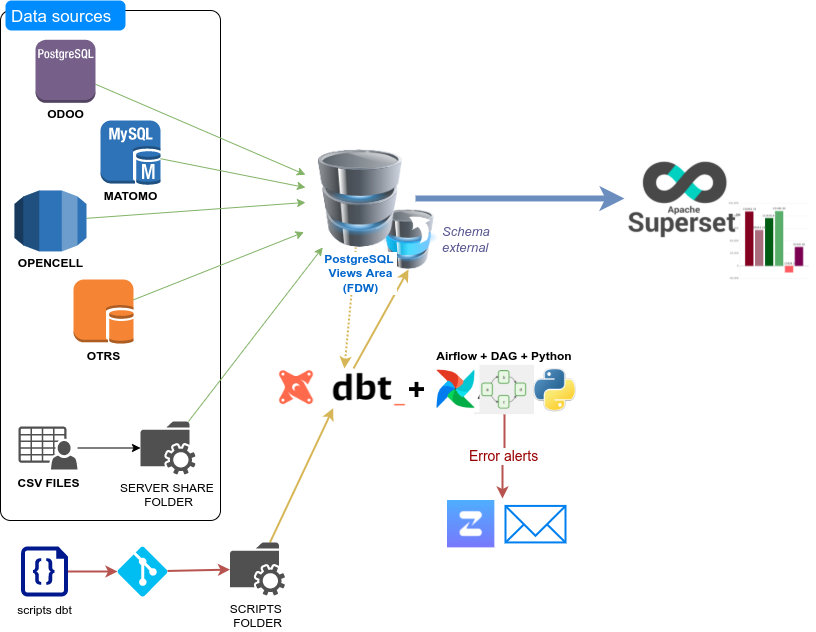
Creació estructura FDW
Com hem comentat abans, calia consultar diverses fonts de dades a la vegada, a l’inici del projecte sabíem les taules que s’estaven utilitzant actualment, però no les que es podien utilitzar en un futur. Es va prendre la decisió de mapejar totes les taules i tots els camps de les taules d’origen amb el FDW, per evitar haver d’anar afegint les taules d’una en una i així permetre als usuaris que poguessin investigar amb les dades actuals.
La generació dels scripts de FDW es va fer a través de consultes SQL que generaven les taules necessàries.

En aquest punt ja es tenia una base de dades postgres que tenia mapejats tots els orígens de dades i que era atacable des de Superset.
La durada de la fase I va ser aproximadament de 2 mesos.
FASE II: Migració Metabase
Un cop implementada l’arquitectura i amb accés a tots els orígens de dades, el següent pas va ser migrar els reports actuals de Metabase.
Per fer la migració es van anar recuperant del Metabase les consultes utilitzades i es van convertir en datasets de Superset.
Les dades que s’explotaven des de Metabase eren totes provinents de l’ERP amb el que es va fer una fase de redisseny per passar d’una consulta per cada indicador a un dataset global que contenia tots els indicadors necessaris.
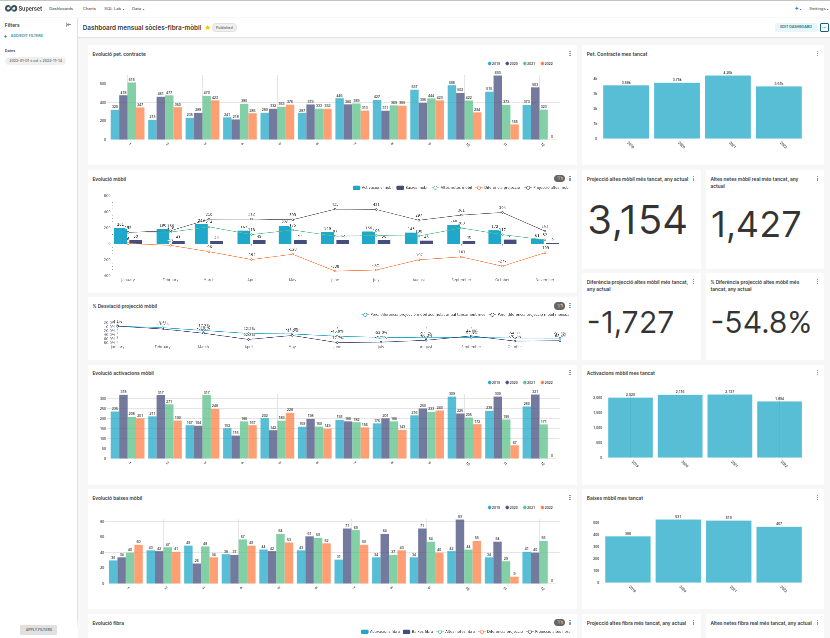
També es van crear dashboards nous basats en les mateixes dades que permetien més flexibilitat d’anàlisi, com per exemple poder canviar la granularitat de les dades de forma dinàmica.
La durada de la fase II va ser aproximadament d’1 mes.
FASE III: Nous dashboards
Un cop migrats els dashboads a Superset es van anar creant noves visualitzacions, algunes d’elles creuant dades dels diferents orígens.
El fet de poder creuar les dades dels diferents orígens de dades va permetre també implementar eines de Data Quality per validar que les dades fossin coherents entre els diferents orígens.
En aquest punt ja van començar a aparèixer algunes consultes que el rendiment era molt lent, amb el que es van implementar els primers scripts de DBT per tal de poder persistir algunes dades i que la velocitat fos major.
Els DBT estan en un GIT que el servidor s’encarrega de fer pull quan hi ha canvis en el codi. D’aquesta forma es pot tenir un històric dels canvis que hi ha hagut a l’script, i, si calgués, es podria forçar a fer merge request abans de fer les pujades definitives.
Aquests scripts de DBT es criden des d’Airflow, i, en cas d’error, envia una notificació a Zulip, fent que o s’hagi d’estar mirant manualment els panell d’Airflow cada dia.
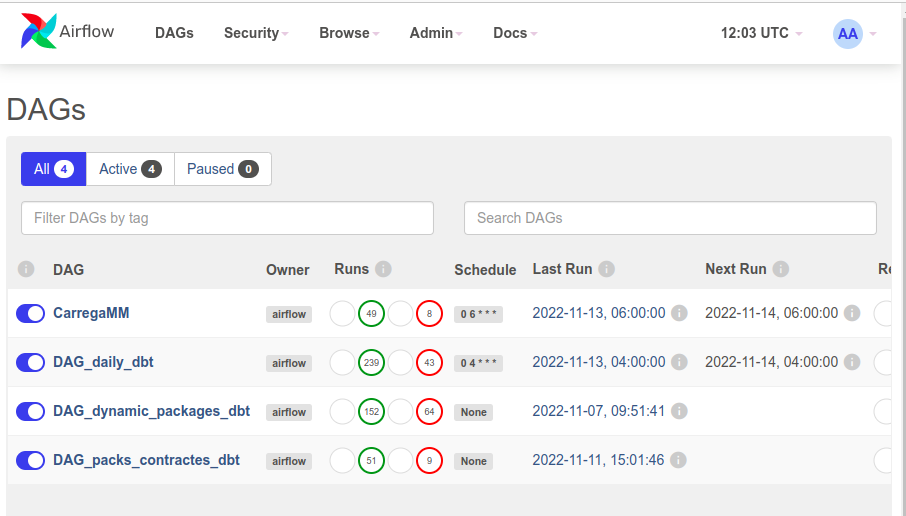
En aquest punt els usuaris ja podien consultar dashboards amb dades dels diferents orígens, però encara eren 100% dependents que algú els crees la consulta SQL per introduir als Datasets de Superset necessaris per a fer els informes.
El següent punt era implementar estructures de dades per permetre crear informes per ells mateixos.
Aquesta fase va durar, inicialment, uns 5 mesos. Aquesta fase es dinàmica, ja que cada nou requeriment dels usuaris implica una nova creació de dashboards. Tot i que es plantegi crear estructures self service, sempre hi haurà casos on calgui feina tècnica que no poden fer els usuaris directament.
FASE IV: Self service
La fase de self service va començar amb el disseny de les diferents estructures de dades.
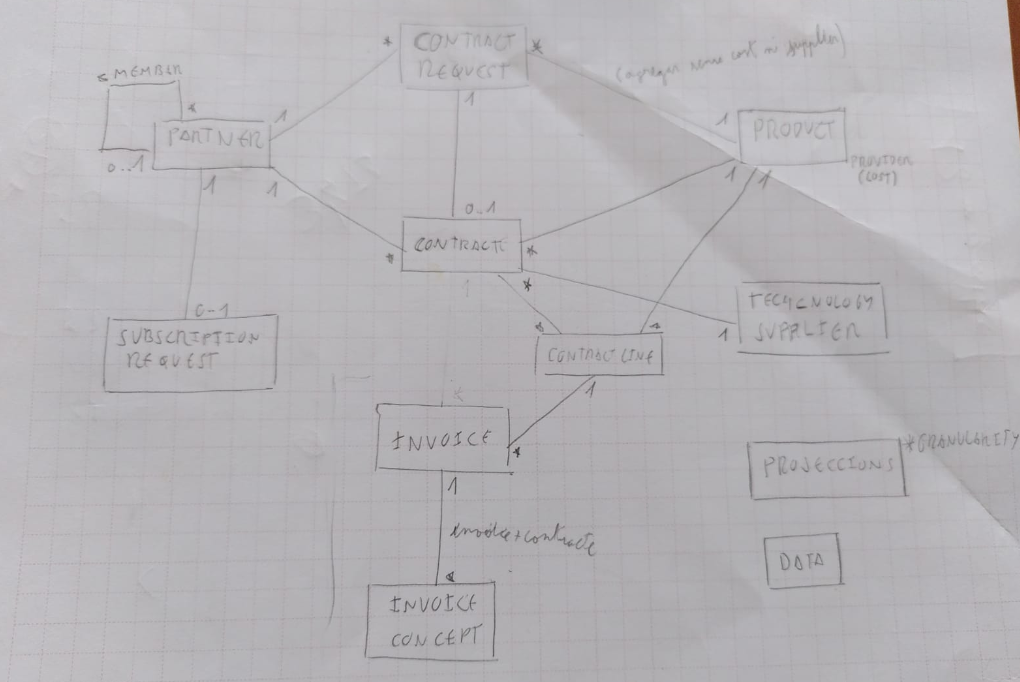
A partir d’aquest disseny es va crear el procés de transformació de dades amb DBT. Aquest procés és un procés ETL (Extraction-Transform-Load) habitual, on l’Extraction correspon al FDW i el DBT s’encarrega del Transform i el Load.
Crear el procés amb DBT ha permès generar de forma automàtica la documentació sobre el data lineage de cada taula self service.

I també sobre cada camp que hi ha a les taules.
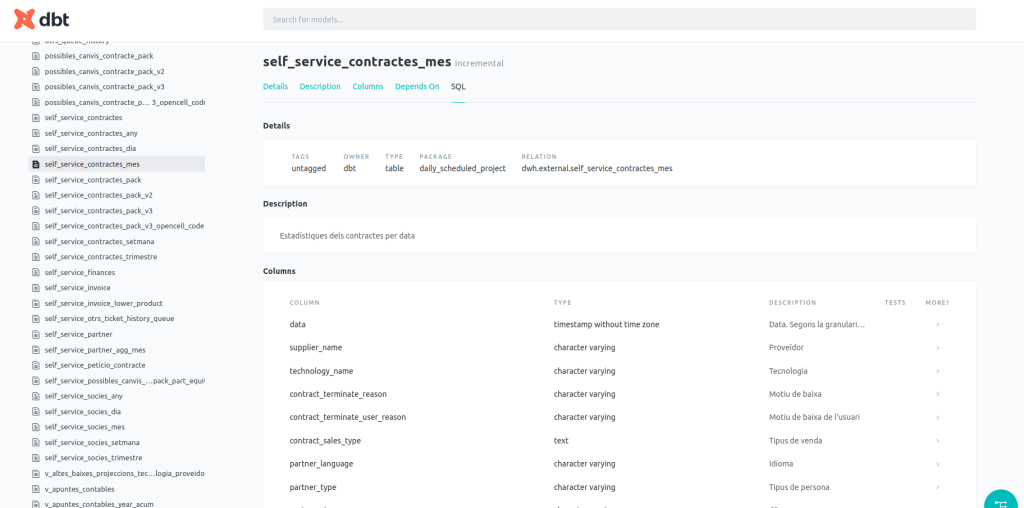
Un cop creades les taules amb el DBT es van crear els datasets de Superset que ja podien ser utilitzats pels usuaris.
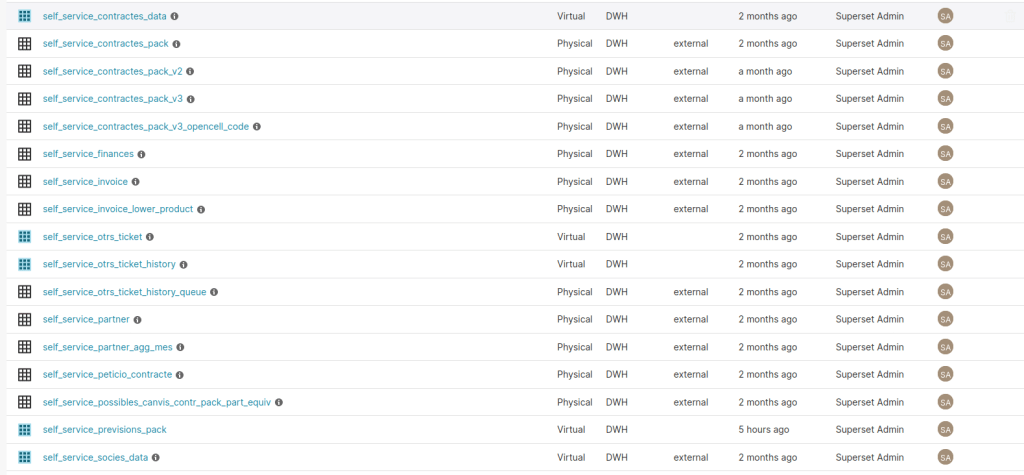
Aquesta fase es va trigar 2 mesos a implementar-la. De la mateixa forma que la fase anterior, aquesta fase és dinàmica i quan apareixen nous conceptes de negoci a analitzar cal crear noves estructures de self service.
FASE V: Escenaris What-if – Previsió i pressupostació
Un cop hi havia els principals dashboards creats i els datasets de self service per a que els usuaris es creessin els seus propis informes, el següent pas va ser dotar la capacitat de poder fer anàlisis What-if.
Per a fer aquests anàlisis els usuaris han de poder canviar dades de forma dinàmica (ex. preus dels productes, % de variació de vendes, etc), per poder veure quin impacte tenen aquests canvis.
La introducció d’aquestes dades es fa a través de fitxers CSV que es pujen a un SFTP. Aquests fitxers CSV estan mapejats com a taula a través de FDW. Un cop mapejats els fitxers ja es poden utilitzar com si fossin una taula més de la base de dades i crear consultes i datasets creuant-los amb la resta de taules.
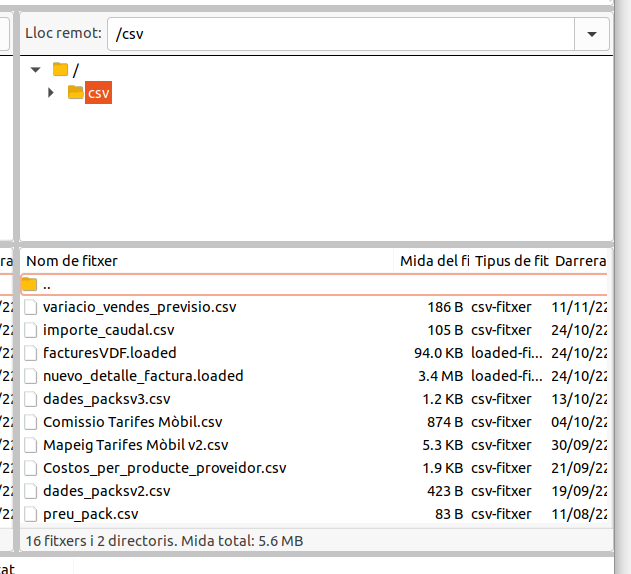
Aquesta fase, igual que les anteriors és dinàmica en el temps depenent dels requeriments dels usuaris.
Actualment el projecte de Som Connexió duu 13 mesos de durada.
Propers passos
A part de creació de nous dashboards, estructures self service i anàlisi what if que puguin anar sortint, el proper pas principal és buscar eines alternatives a Superset, per tal de cobrir les mancances de visualtizació que té, com poden ser: l’exportació a excel, la complexitat de la UI a l’hora de crear alguns informes, la visualització de les taules pivot o noves funcionalitats com els filtres fent click a gràfics. Algunes de les eines que s’estan posant sobre la taula són EDA o Knowage.
La part positiva de l’arquitectura muntada és modular i que es pot connectar qualsevol tipus de visualitzador a la base de dades, sense necessitat d’haver de tocar el disseny.
Altres vessants del projecte
El projecte de Business Intelligence de Som Connexió també té una part d’analítica web. Actualment s’estan analitzant les dades a través de Matomo (https://coopdevs.org/analitica-web-per-a-leconomia-social-i-solidaria/ ). També s’estan analitzant altres eines de codi lliure com Plausible, per tal de tenir una visió el més complerta possible de les visites.
Les dades d’analítica web també estan en una base de dades, que pot ser integrada amb la resta de dades i poder fer un anàlisi 360º de la cooperativa.
Amb aquest cas pràctic hem pogut veure la implemetació d’un sistema de Business Intelligence de llarga durada , contraposant-lo amb el cas de l’Associacio per la Desenvolupament dels Bancs del Temps (https://coopdevs.org/business-intelligence-un-cas-practic-associacio-per-al-desenvolupament-dels-bancs-de-temps/ ) que era un servei acotat en el temps.